 移除树木建筑的DEM
移除树木建筑的DEM
# 1.数据概况
高程数据是许多应用的基础,特别是在地球科学领域。最新的全球高程数据包含了森林和建筑的假象,限制了其在需要精确地形高度的应用中的作用,例如洪水模拟。
在本研究中通过使用使用机器学习从哥白尼数字高程模型中去除建筑物和森林,首次产生了30m空间分辨率无建筑物和森林的全球数字高程模型数据集。研究通过在这些数据来自12个国家,涵盖广泛的气候区和城市范围的参考高程数据上训练校正算法,这与以前在单一国家的数据上训练的DEM相比,这种方法具有更广泛的适用性。该套算法方法将建筑区的平均绝对垂直误差从1.61米减少到1.12米,将森林区的平均绝对垂直误差从5.15米减少到2.88米。新的数字高程模型比现有的全球数字高程模型更准确,将会更好服务于高质量全球地形信息的应用和模型。
# 2.研究现状
全球尺度或近全球尺度的DEM数据大多是以3角秒(约90米),以及最近的1角秒(约30米)的空间分辨率。3角秒网格间距的全球DEM包括广泛使用的航天飞机雷达地形任务SRTM,以及MERIT、TanDEM-X 90和Copernicus GLO-90。1角秒的产品包括ASTER GDEM V3、AW3D30 v3.2 、SRTM、NASADEM和最近的Copernicus DEM GLO-30(以下简称COPDEM30)。
COPDEM30和TanDEM-X数据作为最新和最准确的DEM数据。可以通过COPDEM30准确地解析大多数特征,Guth和Geoffroy甚至说COPDEM30应该成为全球DEM的 "黄金标准"。因此,COPDEM30被选为这项工作的基础,用于制作全球裸地DEM。
# 3.生产方法
使用随机森林回归模型的机器学习技术,本研究从COPDEM30中移除了建筑物和树的高度偏差,以创建一个名为 FABDEM(Forest And Buildings removed Copernicus DEM)的新数据集。新数据集在60∘S和80∘N 之间,网格间距为1弧秒(约30米),是第一个同时删除树木和建筑物的数字高程模型数据集。通过参考高程数据进行验证,并将其与其他全球 DEM 进行比较。与现有的全球DEM相比,FABDEM的分辨率和精度的提高将使许多对地形的表现非常重要的应用受益。洪水淹没模型尤其如此,因为地形是决定水流的关键因素,从而决定了洪水的位置。

制作FABDEM的工作流程包括三个阶段:
(1)数据准备,包括处理预测数据和参考DEMs;
(2)随机森林校正,分别对森林和建筑物进行移除;
(3)后期处理,合并校正后的DEMs,填补不真实的坑洞,并应用平滑滤波器。
# 4.数据基础
FABDEM 生产中使用的所有数据都经过处理并重新网格化到COPDEM30网格(EPSG 4326投影,水平网格间距为1弧秒)。然后将预测数据和参考DEM编译成随机森林模型使用的表格数据格式。选择了被确定为对估计DSM中与建筑物和树木有关的异常情况有用的预测数据。描述森林高度、森林覆盖率和建筑物足迹的关键数据集具有与COPDEM30相似的分辨率(10-100米),使它们能够提供网格单元级别的信息。
使用随机森林模型从森林区域的参考数据 (LiDAR) 预测 COPDEM30 高程和地形高程之间的差异。因此,需要变量来估计森林的高度和森林的冠层覆盖率。因为 COPDEM30 中使用的雷达信号穿透树冠的方式取决于树木的特性和雷达特性。
森林高度的预测数据取自 Global Forest Canopy Height 2019 数据集。国际空间站上的全球生态系统动力学调查(GEDI) LiDAR数据已与Landsat GLAD ARD数据集成,以估计30m网格为间距获取森林冠层高度。在2019年全球森林冠层高度数据集(52°N 以上)之外的区域,我们使用ICESat-2 L3A土地和植被高度(v4.0)ATL-08数据估计冠层高度。
建立了一个单独的随机森林模型来预测 COPDEM30高程与LiDAR城市地区地形高程之间的差异。多个预测数据集用于建筑物拆除,以表征与建筑物高度相关的因素,例如建筑物占地面积、人口和社会经济指标。预测数据集包括人口密度 (WorldPop)、旅行时间、夜间灯光、城市建筑足迹(World Settlement Footprint)、人均建成区、GDP和平均绿度GHS-UCDB R2019A。
# 5.质量验证
在建立随机森林模型时,75%的数据样本被用于训练模型,25%的数据样本被保留下来,只用于验证。
对于城市校正,参考COPDEM30数据的平均绝对误差(MAE)为1.72米,在训练样本上的预测结果降为0.94米,而在验证样本上的预测结果的MAE为1.35米。对于森林模型(北纬52°以南),分割样本验证结果为。COPDEM30数据的MAE为7.2米,对训练样本的预测MAE为3.52米,对验证样本的预测MAE为6.55米。最后,对于北方森林模型(北纬52°以北),分割样本验证结果是COPDEM30数据的MAE为3.77米,对训练样本的预测MAE为1.72米,对验证样本的预测MAE为3.24米。
在每种情况下,验证样本的误差都大于训练样本,但与COPDEM30数据相比有所减少。上述分割样本验证的结果是在应用任何后处理之前,针对随机森林模型预测的参考数据的误差。
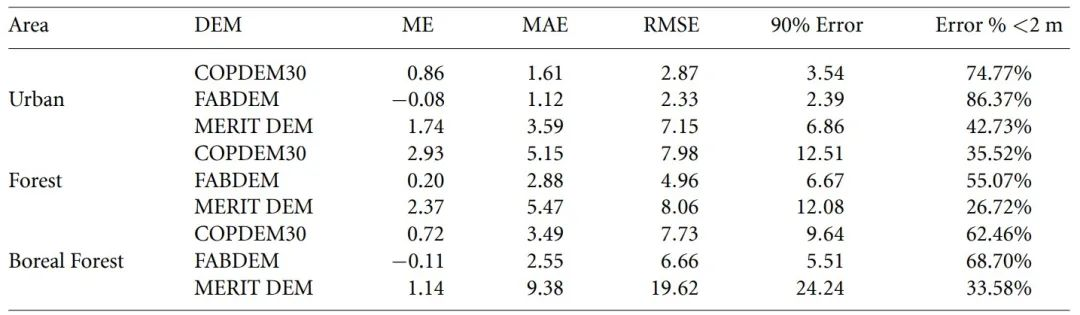
将FABDEM与COPDEM30和MERIT DEM与参考数据进行比较的直方图。每个包含参考数据的图块采样1000个网格单元。注意:此处使用的参考数据与用于训练机器学习模型的数据集相同,但是是不同的随机样本。
将COPDEM30、FABDEM和MERIT DEM与每种校正方法的参考DEM进行比较的误差统计。仅对应用了相应类型的FABDEM校正的陆地单元进行比较。ME是平均误差,MAE是平均绝对误差,RMSE是均方根误差。
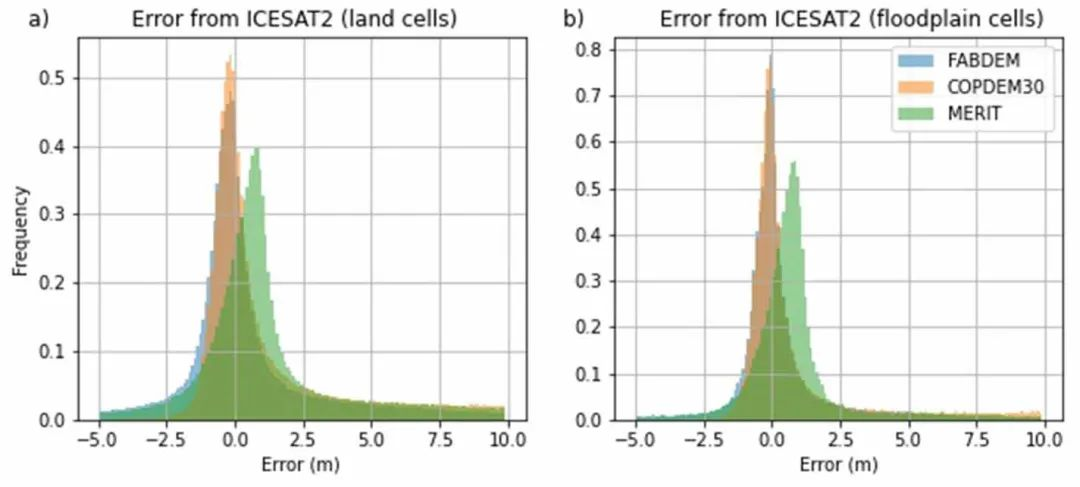
将FABDEM与COPDEM30和MERIT DEM与 ICESat2高程进行比较的直方图。从全球1900个随机选择的瓦片(占瓦片的10%)中抽取1000个样本。(a)比较所有陆地单元 (b)比较在GFPLAIN 250m数据集 中识别为洪泛区的单元。
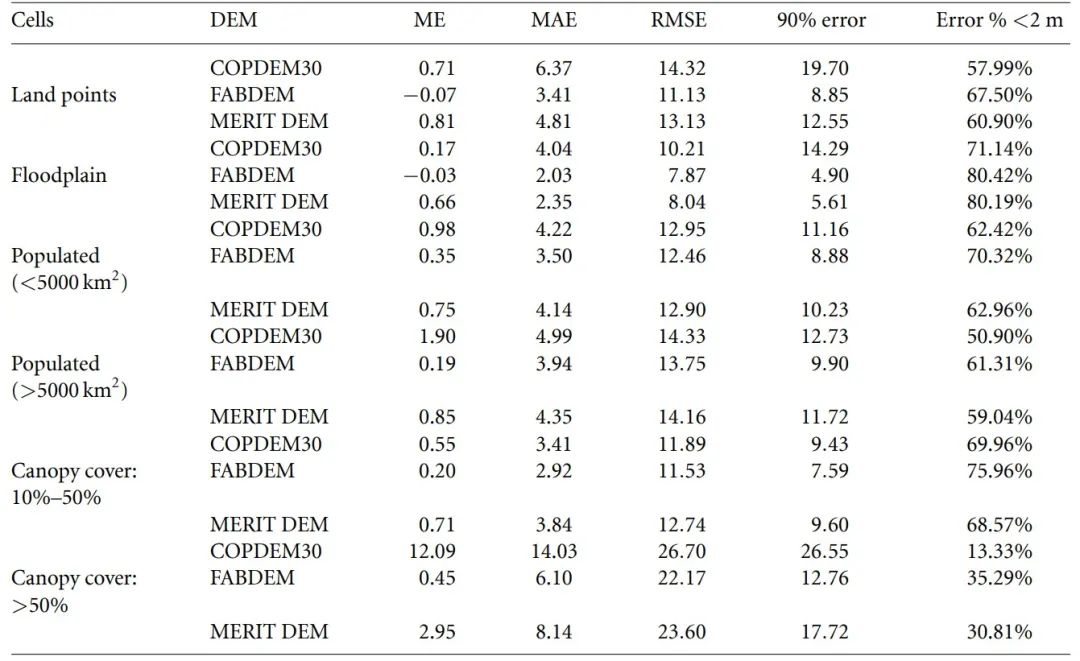
COPDEM30、FABDEM和MERIT DEM与陆地点、洪泛区点(由GFPLAIN250m数据集定义)、树冠覆盖和人口密度的ICESat2高程数据进行比较的误差统计。ME是平均误差,MAE是平均绝对误差,RMSE是均方根误差。
# 6.视觉评估
为了定性地确定应用于FABDEM的校正的好处,我们展示了参考数据的空间图和包括 FABDEM 在内的五种不同的全球DEM。显示了四个位置:一处美国迈阿密,与随机森林模型训练中未包含的参考DEM进行比较;两处荷兰和澳大利亚,包括在随机森林模型的训练中;一处湄公河三角洲,在没有高质量本地DEM 的情况下比较全球DEM。
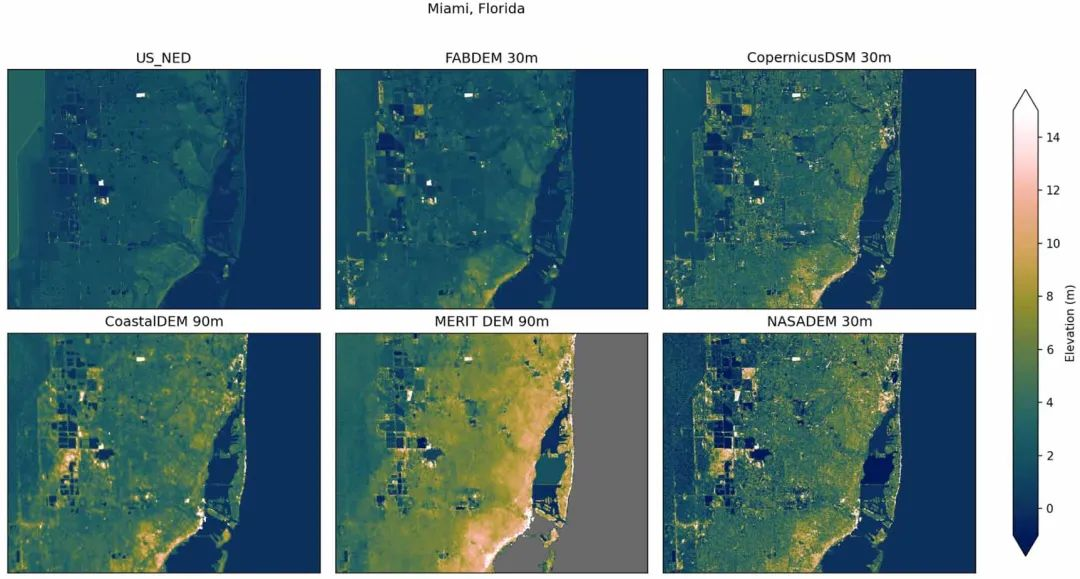
美国佛罗里达州(包括迈阿密)地区不同DEM 的比较。涵盖80.5°–80°W,25.7°–26°N。US_NED是美国国家高程数据集(该图像的某些西部范围不是 LiDAR)

荷兰地区不同DEM的比较。涵盖 5.268°–5.582°E、51.595°–51.934°N。AHN3是荷兰国家高程数据集。注意:一些水域被遮盖并在AHN3中显示为灰色。
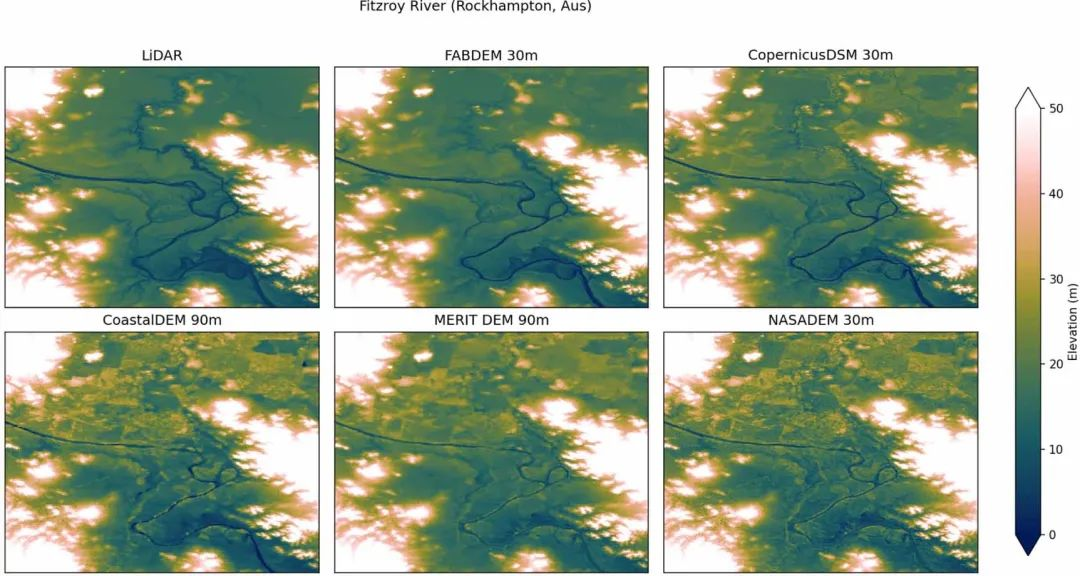
澳大利亚罗克汉普顿Fitzroy河上不同DEM的比较。域涵盖150.25°–150.475°E,23.3°-23°S。注意:在20m 以上,Coastal DEM没有应用修正。

湄公河三角洲部分地区不同DEM的比较。涵盖 106°–106.8°E,10°–10.35°N。无法在该位置访问地面实况 LiDAR 图像进行比较。
# 7.论文及数据获取
引用格式:
Hawker L, Uhe P, Paulo L, et al. A 30 m global map of elevation with forests and buildings removed[J]. Environ. Res. Lett. 17(2022) 024016.
原文链接:
https://doi.org/10.1088/1748-9326/ac4d4f
访问链接:
https://data.bris.ac.uk/data/dataset/25wfy0f9ukoge2gs7a5mqpq2j7
出版单位:University of Bristol
出版时间:17.Dec.2021
